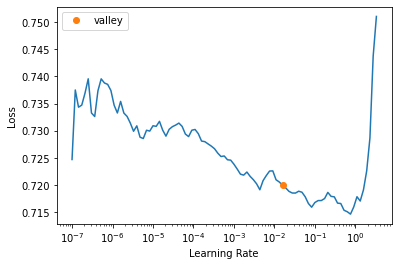
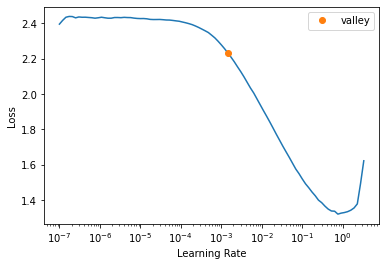
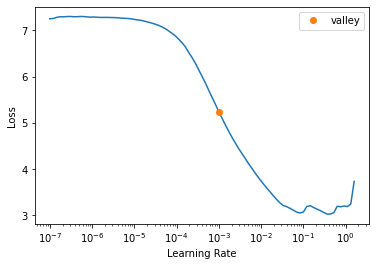
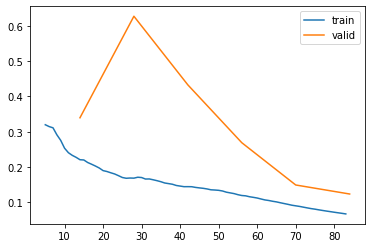
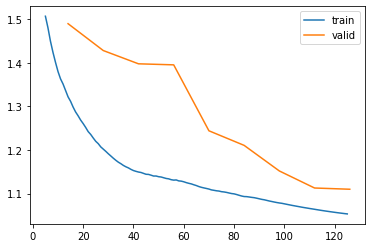
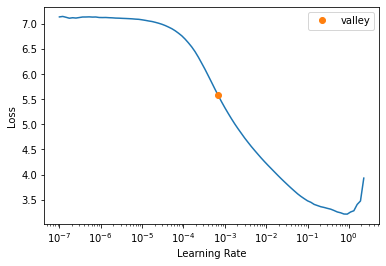
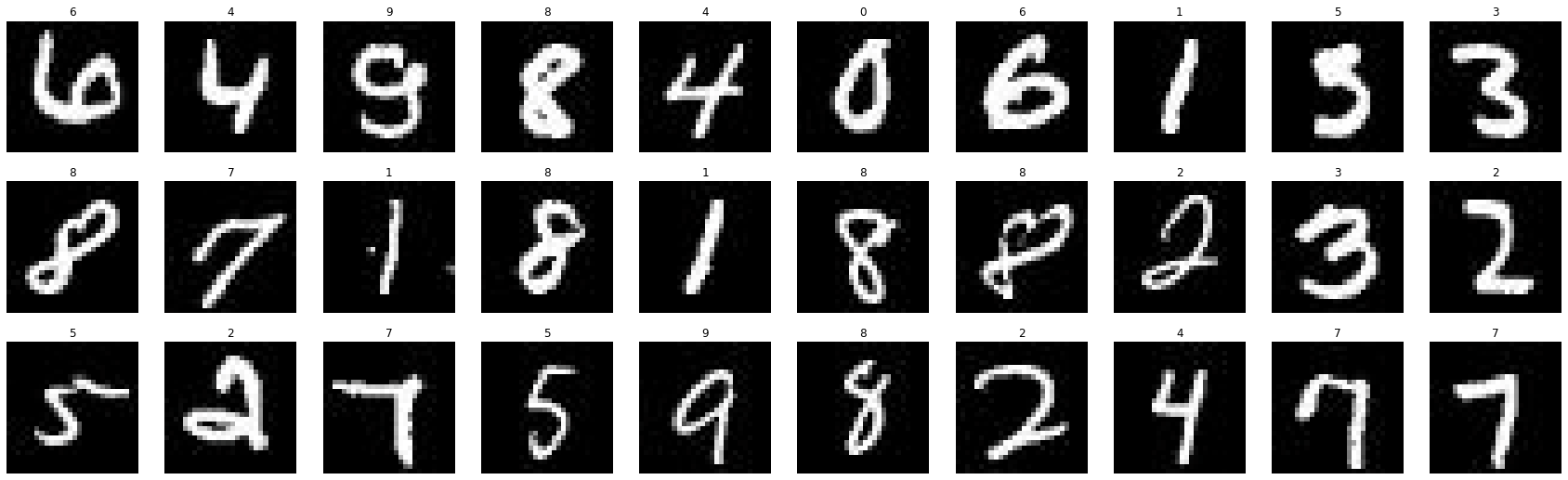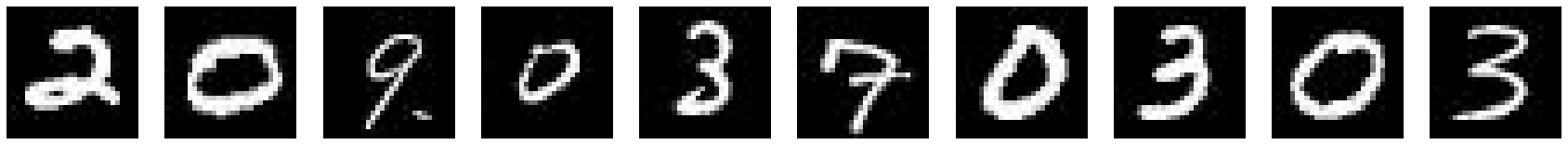!nvidia-smiThu Oct 31 02:47:40 2024
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.116.04 Driver Version: 525.116.04 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA RTX A4000 Off | 00000000:00:05.0 Off | Off |
| 41% 37C P8 16W / 140W | 1MiB / 16376MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+