try: import fastkaggle
except ModuleNotFoundError:
!pip install -Uq fastkaggle fastai
from fastkaggle import *
import fastai
from fastai.vision.all import *
fastai.__version__'2.7.19'このノートではコードベースで、文脈ベースの画像分類モデルを見ていきます。深層学習にはfastaiライブラリーを、データセットはkaggleのdl-2024-autum-exp-2競技で提供された画像を使用します。基の論文のリンクです。そもそも自己教師あり学習とはなんぞやと言う方は、こちらのブログをどうぞ。ざっくりと言えば、ラベル付きの画像データが少ない時、自己教師ありでモデルをファインチューニングさせ、目的のタスクの精度を向上させる学習手法です。従来の教師あり学習との違いは下記の通りです。
従来(教師あり学習)のファインチューニング:
①imagenetで学習されたモデル → ②タスク特化のデータを学習
自己教師ありでのファインチューニング:
①imagenetで学習されたモデル → ②(NEW) 自己教師あり学習 → ③タスク特化のデータを学習
–
実装手順:
最新のfastaiライブラリー(記事作成時点で2.7.19)が入っていることを確認してください。このノートのコードは、古いバージョンでは動きません。
try: import fastkaggle
except ModuleNotFoundError:
!pip install -Uq fastkaggle fastai
from fastkaggle import *
import fastai
from fastai.vision.all import *
fastai.__version__'2.7.19'競技参加の同意・APIキーの取得を、テータセットのインストール前に行っていきましょう。
!mkdir /root/.config/kaggle
!touch /root/.config/kaggle/kaggle.jsonmkdir: cannot create directory ‘/root/.config/kaggle’: File existscomp = "dl-2024-autum-exp-2"
path = setup_comp(comp)
path.ls()Warning: Your Kaggle API key is readable by other users on this system! To fix this, you can run 'chmod 600 /root/.config/kaggle/kaggle.json'(#2) [Path('dl-2024-autum-exp-2/sample_submission.csv'),Path('dl-2024-autum-exp-2/food-11_DL_2024')]!rm -rf temp
!mkdir temp
!cp -r {path}/food-11_DL_2024/training/labeled temp/training
!cp -r {path}/food-11_DL_2024/validation temp/validation
!cp -r {path}/food-11_DL_2024/testing temp/testingimg_files = get_image_files(path); img_files(#10512) [Path('dl-2024-autum-exp-2/food-11_DL_2024/training/unlabeled/00/6022.jpg'),Path('dl-2024-autum-exp-2/food-11_DL_2024/training/unlabeled/00/1332.jpg'),Path('dl-2024-autum-exp-2/food-11_DL_2024/training/unlabeled/00/3737.jpg'),Path('dl-2024-autum-exp-2/food-11_DL_2024/training/unlabeled/00/4200.jpg'),Path('dl-2024-autum-exp-2/food-11_DL_2024/training/unlabeled/00/2541.jpg'),Path('dl-2024-autum-exp-2/food-11_DL_2024/training/unlabeled/00/1649.jpg'),Path('dl-2024-autum-exp-2/food-11_DL_2024/training/unlabeled/00/3191.jpg'),Path('dl-2024-autum-exp-2/food-11_DL_2024/training/unlabeled/00/5376.jpg'),Path('dl-2024-autum-exp-2/food-11_DL_2024/training/unlabeled/00/2739.jpg'),Path('dl-2024-autum-exp-2/food-11_DL_2024/training/unlabeled/00/5792.jpg'),Path('dl-2024-autum-exp-2/food-11_DL_2024/training/unlabeled/00/4384.jpg'),Path('dl-2024-autum-exp-2/food-11_DL_2024/training/unlabeled/00/5015.jpg'),Path('dl-2024-autum-exp-2/food-11_DL_2024/training/unlabeled/00/3123.jpg'),Path('dl-2024-autum-exp-2/food-11_DL_2024/training/unlabeled/00/6487.jpg'),Path('dl-2024-autum-exp-2/food-11_DL_2024/training/unlabeled/00/5924.jpg'),Path('dl-2024-autum-exp-2/food-11_DL_2024/training/unlabeled/00/6366.jpg'),Path('dl-2024-autum-exp-2/food-11_DL_2024/training/unlabeled/00/3052.jpg'),Path('dl-2024-autum-exp-2/food-11_DL_2024/training/unlabeled/00/4788.jpg'),Path('dl-2024-autum-exp-2/food-11_DL_2024/training/unlabeled/00/6755.jpg'),Path('dl-2024-autum-exp-2/food-11_DL_2024/training/unlabeled/00/3960.jpg')...]今回実装するモデルは、文脈ベースの画像分類(Context Prediction)です。アイデアはシンプルです。画像を3*3(或いは4*4)のパッチに分けて、二つの隣接する画像をSiameseモデルに学習させ、パッチの場所を推測させる学習方法になります。
イメージ図:
| インプット(X)・アウトプット(Y) | モデル設計 |
|---|---|
 |
 |
では、まずは画像を9つのバッチに分ける関数を作ります。
import random
def extract_patches(img, grid_sz=3):
patches, labels = [], []
w, h = img.size
tile_w, tile_h = w//grid_sz, h//grid_sz
for i in range(grid_sz):
for j in range(grid_sz):
box = (j*tile_w, i*tile_h, (j+1)*tile_w, (i+1)*tile_h)
patches.append(img.crop(box))
idx = random.randint(0, len(patches) - 1)
main_patch = patches[idx]
neighbors = [
(-1, -1), (-1, 0), (-1, 1),
(0, -1), (0, 1),
(1, -1), (1, 0), (1, 1)
]
for label, (dx, dy) in enumerate(neighbors):
ni, nj = (idx//grid_sz) + dx, (idx % grid_sz) + dy
if 0 <= ni < grid_sz and 0 <= nj < grid_sz:
neighbor_patch = patches[ni*grid_sz + nj]
labels.append((main_patch, neighbor_patch, label))
return labels
extract_patches(PILImage.create(img_files[0]))[(<PIL.Image.Image image mode=RGB size=170x170>,
<PIL.Image.Image image mode=RGB size=170x170>,
0),
(<PIL.Image.Image image mode=RGB size=170x170>,
<PIL.Image.Image image mode=RGB size=170x170>,
1),
(<PIL.Image.Image image mode=RGB size=170x170>,
<PIL.Image.Image image mode=RGB size=170x170>,
2),
(<PIL.Image.Image image mode=RGB size=170x170>,
<PIL.Image.Image image mode=RGB size=170x170>,
3),
(<PIL.Image.Image image mode=RGB size=170x170>,
<PIL.Image.Image image mode=RGB size=170x170>,
4),
(<PIL.Image.Image image mode=RGB size=170x170>,
<PIL.Image.Image image mode=RGB size=170x170>,
5),
(<PIL.Image.Image image mode=RGB size=170x170>,
<PIL.Image.Image image mode=RGB size=170x170>,
6),
(<PIL.Image.Image image mode=RGB size=170x170>,
<PIL.Image.Image image mode=RGB size=170x170>,
7)]class PatchImage(Tuple):
def show(self, ctx=None, **kwargs):
img1, img2, label = self
if not isinstance(img1, Tensor):
t1, t2 = image2tensor(img1), image2tensor(img2)
else: t1, t2 = img1, img2
line = t1.new_zeros(t1.shape[0], t1.shape[1], 5)
return show_image(torch.cat([t1, line, t2], dim=2),
title=label, ctx=ctx)
imgs_label = random.choice(extract_patches(PILImage.create(img_files[0])))
PatchImage(imgs_label).show();
画像を3*3のパッチに分割したら、その中の1ペア(二つの画像)とそのラベル(隣接するパッチ2の位置)をランダムに選びます。ここでの注意点は、画像をfastaiライブラリー型のPILImageに、またラベルをtensor型に変換する必要がある点です。後の画像処理(ResizeやToTensor)はPILImage型にだけ適用されるトランスフォーマーです。逆にPILImage型への変換なしでは、必要な画像処理は適用されません。またfastaiの古いバージョンではここでエラーが出ます。
class PatchTransform(Transform):
def __init__(self, grid_sz=3):
self.grid_sz = grid_sz
def encodes(self, f):
img = PILImage.create(f)
img1, img2, label = random.choice(extract_patches(img, grid_sz=self.grid_sz))
img1, img2, label = PILImage.create(img1), PILImage.create(img2), torch.tensor(label).long()
return PatchImage((img1, img2, label))
PatchTransform()(img_files[0]).show();
tls = TfmdLists(img_files, PatchTransform(), splits=RandomSplitter(0.1)(img_files))
show_at(tls.valid, 1);
データセットを用意したら、バッチの形(batch number, channel, height, width)であることを確認します。今回のデータセットは2つの画像と1つのラベルです。
dls = tls.dataloaders(after_item=[Resize(128), ToTensor],
after_batch=[IntToFloatTensor, *aug_transforms(do_flip=False, mult=0.03), Normalize.from_stats(*imagenet_stats)])
x1, x2, y = dls.one_batch()
x1.shape, x2.shape, y.shape(torch.Size([64, 3, 128, 128]),
torch.Size([64, 3, 128, 128]),
torch.Size([64]))データローダーの用意ができましたら、次はモデル設計です。ここではxresnetを使用して設計を簡略化しています。詳しい実装方法はfastai のチュートリアルを参照してください。大事な実装点は、エンコーダーには重みを共有したCNNモデル(resnet以外も可)を使用します。model_meta[arch]["cut"]でモデルのbody部分(headを取り除いた)の情報を取得しています。
class PatchModel(Module):
def __init__(self, encoder, head):
self.encoder, self.head = encoder, head
def forward(self, x1, x2):
feats = torch.cat([self.encoder(x1), self.encoder(x2)], dim=1)
return self.head(feats)
encoder = create_body(xresnet18(pretrained=True), cut=model_meta[xresnet18]["cut"])
head = create_head(512*2, 8, bn_final=True)
def splitter(model): return [params(model.encoder), params(model.head)]
learn = Learner(dls, PatchModel(encoder, head),
splitter=splitter,
loss_func=LabelSmoothingCrossEntropyFlat(),
metrics=accuracy).to_fp16()
learn.lr_find(suggest_funcs=(valley, slide))SuggestedLRs(valley=0.007585775572806597, slide=0.17378008365631104)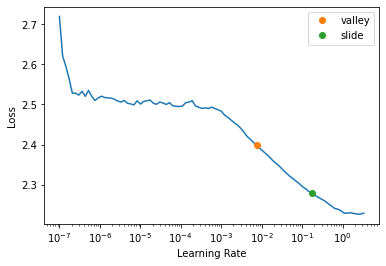
モデルのトレーニングを開始します。学習後は、モデルのエンコーダー(body部分のみ)の重みを保存します。後の分類タスクに、保存された学習済み重みを使用します。
learn.fine_tune(6, 3e-2, wd=0.01)| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 2.028306 | 2.027441 | 0.235966 | 00:34 |
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 1.890716 | 1.852404 | 0.310181 | 00:39 |
| 1 | 1.775437 | 1.727063 | 0.393911 | 00:39 |
| 2 | 1.672039 | 1.589555 | 0.458611 | 00:40 |
| 3 | 1.591938 | 1.518641 | 0.483349 | 00:40 |
| 4 | 1.530126 | 1.479046 | 0.514748 | 00:40 |
| 5 | 1.509492 | 1.459406 | 0.535680 | 00:39 |
torch.save(learn.model.encoder.state_dict(), path/"pretrained.pt")画像分類(本来のタスク)のデータセットを用意します。ここでのポイントは、トレーニング画像のサイズを自己教師あり学習時のサイズと合わせる点です。
def get_dls(size=128, bs=128):
return DataBlock(
blocks=(ImageBlock, CategoryBlock),
get_items=get_image_files,
get_y=parent_label,
splitter=GrandparentSplitter(train_name="training", valid_name="validation"),
item_tfms=Resize(512),
batch_tfms=[*aug_transforms(size=size, min_scale=0.7),
Normalize.from_stats(*imagenet_stats)]
).dataloaders(Path("temp"), bs=bs, num_workers=8)
dls = get_dls(128, 128)
dls.show_batch(max_n=25, nrows=5, ncols=5)
print(f"training sample is : {len(dls.train_ds)}")
print(f"training sample is : {len(dls.valid_ds)}")
print(f"unique targets are: {dls.vocab}")training sample is : 2464
training sample is : 561
unique targets are: ['00', '01', '02', '03', '04', '05', '06', '07', '08', '09', '10']データセットを用意したら、モデルのトレーニングに移ります。ここでのポイントは、先ほどの学習済み重みを使用する点です。使用するエンコーダーは同じモデル設計(ここではxresnet18)であることも注意点です。encoder.load_state_dictメソッドで学習済みの重みを取得します。
def load_learned_encoder(pretrained=False):
encoder = create_body(xresnet18(pretrained=True), cut=model_meta[xresnet18]["cut"])
if pretrained:
print("Started loading weights")
encoder.load_state_dict(torch.load(path/"pretrained.pt"))
print("Finished loading weights")
return encoder
def get_learner(pretrained=False):
return vision_learner(dls, load_learned_encoder,
normalize=False,
pretrained=pretrained,
custom_head=create_head(256, dls.c, bn_final=True),
loss_func=LabelSmoothingCrossEntropyFlat(),
metrics=accuracy).to_fp16()
learn = get_learner(pretrained=True)
learn.lr_find(suggest_funcs=(valley, slide))Started loading weights
Finished loading weightsSuggestedLRs(valley=0.0063095735386013985, slide=0.033113110810518265)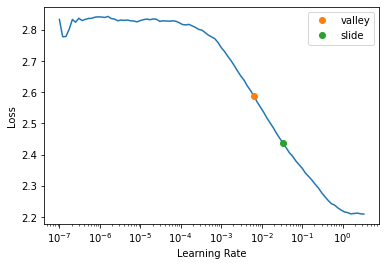
learn.fine_tune(8, 1e-2, wd=0.1)| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 2.256169 | 2.391047 | 0.363636 | 00:13 |
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 1.851541 | 1.771621 | 0.461676 | 00:14 |
| 1 | 1.791788 | 1.689643 | 0.518717 | 00:14 |
| 2 | 1.748776 | 1.635341 | 0.511586 | 00:14 |
| 3 | 1.696687 | 1.599028 | 0.516934 | 00:14 |
| 4 | 1.646810 | 1.560353 | 0.547237 | 00:14 |
| 5 | 1.605079 | 1.562763 | 0.540107 | 00:14 |
| 6 | 1.562018 | 1.550508 | 0.556150 | 00:15 |
| 7 | 1.535239 | 1.541727 | 0.559715 | 00:14 |
ついでに自己教師あり学習なしのモデルの精度を比較してみます。自己教師ありモデルと比べて、おおよそ1.5%くらいaccuracy精度が落ちます。
learn = get_learner(pretrained=False)
learn.fine_tune(8, 1e-2, wd=0.01)| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 2.225904 | 2.442802 | 0.367201 | 00:13 |
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 1.880750 | 1.842755 | 0.433155 | 00:15 |
| 1 | 1.807753 | 1.709808 | 0.484848 | 00:15 |
| 2 | 1.764681 | 1.745654 | 0.479501 | 00:15 |
| 3 | 1.721817 | 1.688701 | 0.493761 | 00:14 |
| 4 | 1.673104 | 1.624697 | 0.527629 | 00:14 |
| 5 | 1.635066 | 1.589912 | 0.524064 | 00:15 |
| 6 | 1.597817 | 1.580481 | 0.536542 | 00:14 |
| 7 | 1.570696 | 1.581818 | 0.541889 | 00:15 |
最後に、インストールしたデータセットを削除します。
!rm -rf {path}
!rm -rf temp
!rm -rf dl-2024-autum-exp-2.zip自己教師あり学習をコードベースで見ていきました。データを用意する際の一番のボトルネックがラベル付けです。手作業のラベル付けなしで、データに含まれている要素から、ラベルをプログラミング的に付与できるのはとても実用的な学習方法です。 次の記事では、今回のモデルの派生型であるジグソーパズルモデルをみていきます。
もしも読者がこのノートを役に立ったと思ったら、リアクションボタンを押してもらえると幸いです。質問や間違いがあれば、以下コメント欄に書き込んでください。